摘要:Pytorch深度学习
autograd 及Variable
Autograd: 自动微分
autograd包是PyTorch中神经网络的核心, 它可以为基于tensor的的所有操作提供自动微分的功能, 这是一个逐个运行的框架, 意味着反向传播是根据你的代码来运行的, 并且每一次的迭代运行都可能不同.
Variable
tensor是硬币的话,那Variable就是钱包,它记录着里面的钱的多少,和钱的流向
线性回归
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
| """
# @Time : 2020/9/14
# @Author : Jimou Chen
"""
import numpy as np
import matplotlib.pyplot as plt
from torch import nn, optim
from torch.autograd import Variable
import torch
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
class LinearRegression(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Linear(1, 1)
def forward(self, x):
output = self.fc(x)
return output
if __name__ == '__main__':
x_data = np.random.rand(100)
noise = np.random.normal(0, 0.01, x_data.shape)
y_data = x_data * 0.1 + 0.2 + noise
print(y_data.shape)
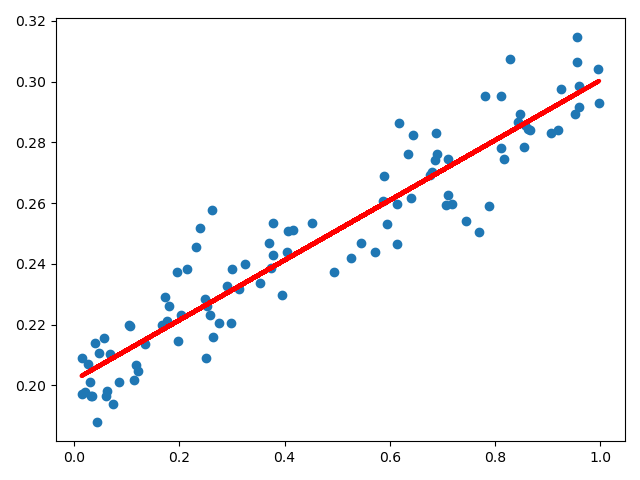
plt.scatter(x_data, y_data)
plt.show()
x_data = x_data.reshape(-1, 1)
y_data = y_data.reshape(-1, 1)
x_data = torch.FloatTensor(x_data)
y_data = torch.FloatTensor(y_data)
inputs = Variable(x_data)
target = Variable(y_data)
model = LinearRegression()
loss = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
for i in range(1000):
out = model(inputs)
mse_loss = loss(out, target)
optimizer.zero_grad()
mse_loss.backward()
optimizer.step()
if i % 200 == 0:
print(i, mse_loss.item())
predict = model(inputs)
plt.scatter(x_data, y_data)
plt.plot(x_data, predict.data.numpy(), 'r-', lw=3)
plt.show()
|
1
2
3
4
5
6
7
8
9
10
| D:\Anaconda\Anaconda3\python.exe D:/Appication/PyCharm/Git/computer-vision/PytorchLearning/LinearRegression/linear_regression.py
(100,)
0 0.1716347187757492
200 0.00019752216758206487
400 0.00011990861094091088
600 0.00011977301619481295
800 0.00011977282701991498
Process finished with exit code 0
|