1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| """
# @Time : 2020/9/6
# @Author : Jimou Chen
"""
from sklearn.linear_model import LogisticRegression
import pandas as pd
import matplotlib.pyplot as plt
import seaborn
import numpy as np
import missingno as msn
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
def label_distribution(data):
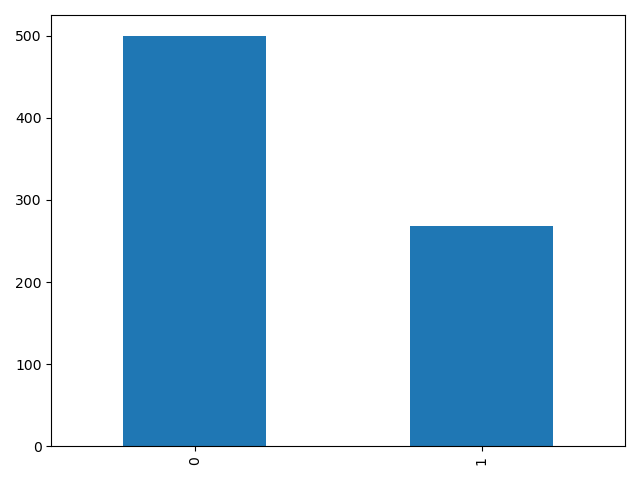
p = data.Outcome.value_counts().plot(kind='bar')
plt.show()
p = seaborn.pairplot(data, hue='Outcome')
plt.show()
p = msn.bar(data)
plt.show()
def handle_data():
data = pd.read_csv('data/diabetes.csv')
print(data.Outcome.value_counts())
handle_col = ['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI']
data[handle_col] = data[handle_col].replace(0, np.nan)
thresh_count = data.shape[0] * 0.8
data = data.dropna(thresh=thresh_count, axis=1)
data['Glucose'] = data['Glucose'].fillna(data['Glucose'].mean())
data['BloodPressure'] = data['BloodPressure'].fillna(data['BloodPressure'].mean())
data['BMI'] = data['BMI'].fillna(data['BMI'].mean())
return data
if __name__ == '__main__':
new_data = handle_data()
label_distribution(new_data)
x_data = new_data.drop('Outcome', axis=1)
y_data = new_data.Outcome
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.3, stratify=y_data)
model = LogisticRegression()
model.fit(x_train, y_train)
pred = model.predict(x_test)
print(classification_report(pred, y_test))
|