摘要:kaggle竞赛题
下载数据集到本地
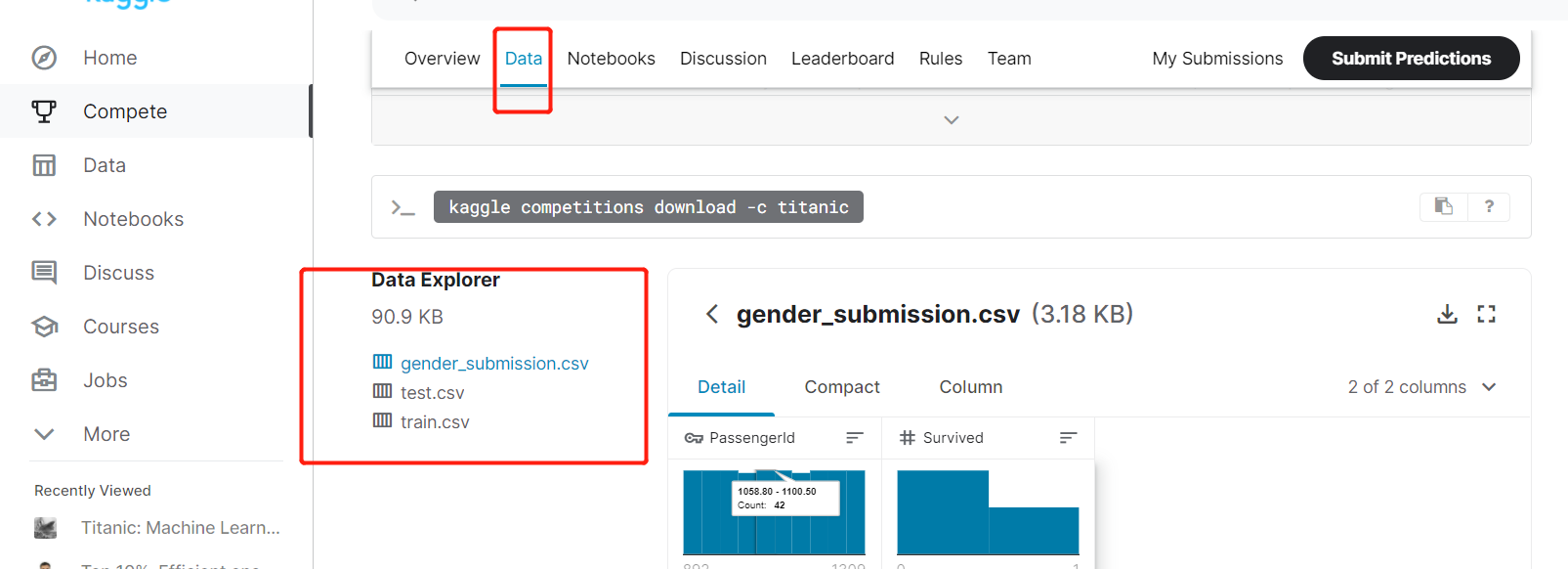

分析数据
- 先知晓各个数据特征的含义,观察一下
- 找到有用的,也就是可以影响到预测标签的数据
- 没有用的数据不用管
处理数据
这些有用的数据中,有些可能是空值
- 如果该列数据较多,就取平均值
- 如果极少,可以删了该行数据
有些有用的数据是字符串,不是数值,需要转化为数值
把各类模型跑一遍,找到分最高的
- 使用交叉验证,对比各个分数
- 这里只列举部分模型,还可以继续添加模型继续对比,或者调参,选出更好的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118"""
# @Time : 2020/9/1
# @Author : Jimou Chen
"""
import pandas as pd
from sklearn.preprocessing import StandardScaler
data = pd.read_csv('train.csv')
# print(data)
'''先处理空缺的数据'''
# 处理空缺的年龄,设为平均年龄
data['Age'] = data['Age'].fillna(data['Age'].median())
# print(data.describe())
# 处理性别,转化维0和1,loc是取数据的,里面传行,列
data.loc[data['Sex'] == 'male', 'Sex'] = 1
data.loc[data['Sex'] == 'female', 'Sex'] = 0
# print(data.loc[:, 'Sex'])
# 处理Embarked,登录港口
# print(data['Embarked'].unique()) # 看一下里面有几类
# 由于'S'比较多,就把空值用S填充
data['Embarked'] = data['Embarked'].fillna('S')
# 转化为数字
data.loc[data['Embarked'] == 'S', 'Embarked'] = 0
data.loc[data['Embarked'] == 'C', 'Embarked'] = 1
data.loc[data['Embarked'] == 'Q', 'Embarked'] = 2
'''接下来选取有用的特征'''
feature = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
x_data = data[feature]
y_data = data['Survived'] # 预测的标签
# 数据标准化
scaler = StandardScaler()
x_data = scaler.fit_transform(x_data)
# print(x_data)
'''处理完数据之后,现在可以使用各自算法看看效果了'''
from sklearn.model_selection import cross_val_score # 导入交叉验证后的分数
# 逻辑回归
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
# 计算交叉验证的误差,分三组
scores = cross_val_score(lr, x_data, y_data, cv=3)
print(scores.mean()) # 求平均
# 神经网络模型
from sklearn.neural_network import MLPClassifier
mlp = MLPClassifier(hidden_layer_sizes=(20, 10), max_iter=2000)
# 计算交叉验证的误差,分三组
scores = cross_val_score(mlp, x_data, y_data, cv=3)
print(scores.mean()) # 求平均
# kNN
from sklearn.neighbors import KNeighborsClassifier
kNN = KNeighborsClassifier(n_neighbors=21)
scores = cross_val_score(kNN, x_data, y_data, cv=3)
print(scores.mean())
# 决策树
from sklearn.tree import DecisionTreeClassifier
# 最小分割样本数,小于4个就不往下分割了
d_tree = DecisionTreeClassifier(max_depth=3, min_samples_split=4)
scores = cross_val_score(d_tree, x_data, y_data, cv=3)
print(scores.mean())
'''下面是集成学习'''
# 随机森林
from sklearn.ensemble import RandomForestClassifier
rf1 = RandomForestClassifier(random_state=1, n_estimators=10, min_samples_split=2)
scores = cross_val_score(rf1, x_data, y_data, cv=3)
print(scores.mean())
# 100棵决策树构成
rf2 = RandomForestClassifier(n_estimators=100, min_samples_split=4)
scores = cross_val_score(rf2, x_data, y_data, cv=3)
print(scores.mean())
# Bagging
from sklearn.ensemble import BaggingClassifier
# 集成rf2,做20次有放回的抽样,由于rf2也是集成学习模型,所以运行时间有点久
bg = BaggingClassifier(rf2, n_estimators=20)
scores = cross_val_score(bg, x_data, y_data, cv=3)
print(scores.mean())
# AdaBoostClassifier
from sklearn.ensemble import AdaBoostClassifier
adb = AdaBoostClassifier(rf2, n_estimators=20)
scores = cross_val_score(adb, x_data, y_data, cv=3)
print(scores.mean())
# Stacking
from mlxtend.classifier import StackingClassifier
stacking = StackingClassifier(classifiers=[bg, mlp, lr],
meta_classifier=LogisticRegression())
scores = cross_val_score(stacking, x_data, y_data, cv=3)
print(scores.mean())
# Voting
from sklearn.ensemble import VotingClassifier
voting = VotingClassifier([('ado', adb), ('mlp', mlp),
('LR', lr), ('kNN', kNN),
('d_tree', d_tree)])
scores = cross_val_score(voting, x_data, y_data, cv=3)
print(scores.mean()) - 结果
1
2
3
4
5
6
7
8
9
10
11
120.7901234567901234
0.8024691358024691
0.8125701459034792
0.8103254769921436
0.8013468013468014
0.819304152637486
0.8204264870931538
0.7991021324354658
0.819304152637486
0.8170594837261503
Process finished with exit code 0 - 可以发现Bagging集成随机森林的效果相对不错
- 接下来就用它来试试
使用该较好模型进行预测
1 | """ |
- 结果
1
2
3
4
5
6
7
8
9
10
11
120.9282296650717703
precision recall f1-score support
0 0.99 0.91 0.95 290
1 0.82 0.98 0.89 128
accuracy 0.93 418
macro avg 0.91 0.94 0.92 418
weighted avg 0.94 0.93 0.93 418
Process finished with exit code 0 - 在迭代测试时发现,效果最好的是score为0.98+
提交
- 有满意的效果就提交看看
- 注意提交的格式
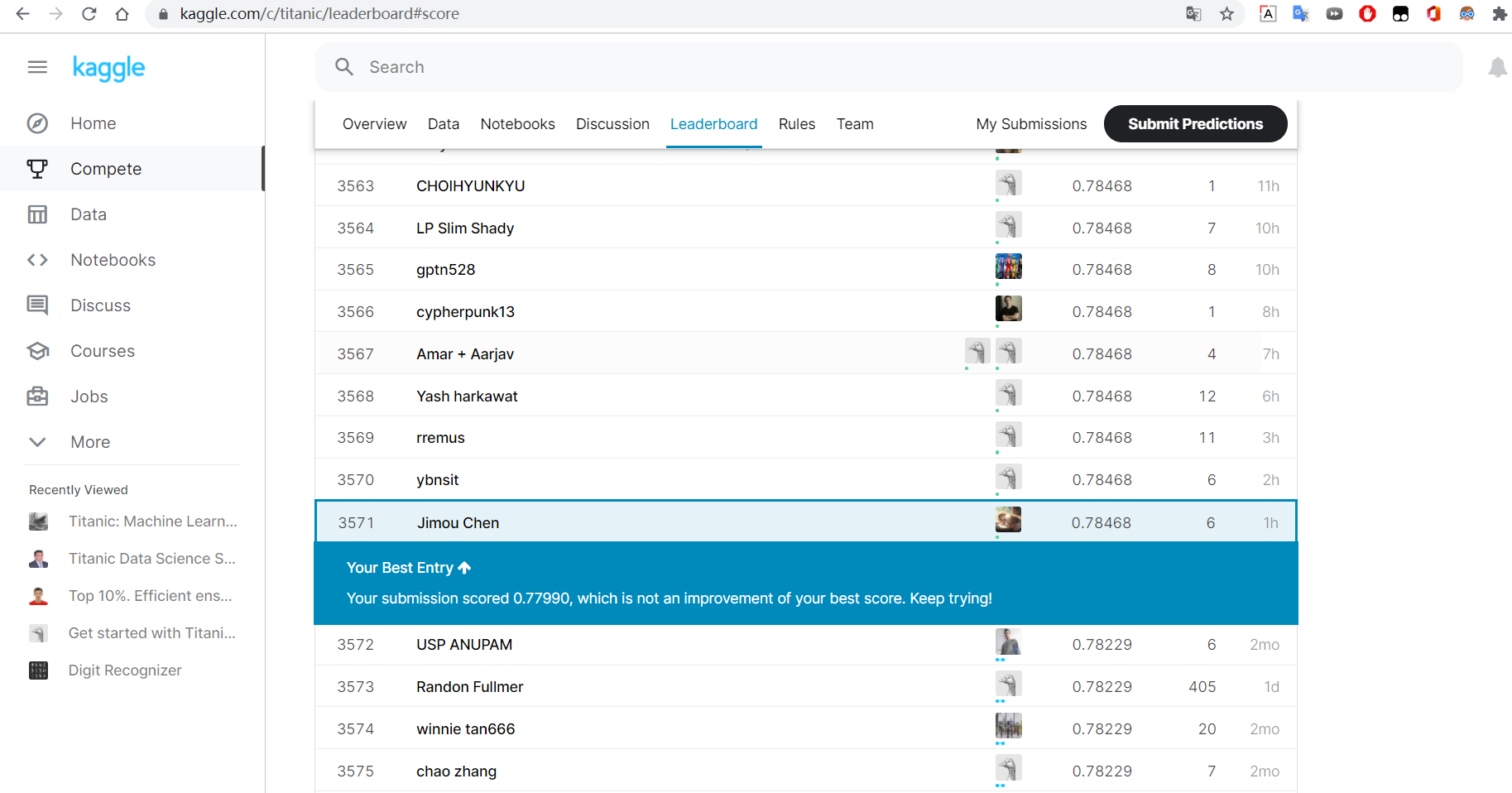
- 直接把生成的csv预测结果文件拖过去

- 然后他就会给出分数和排名
总结
- 要想得到好的预测集上传的高分的话,可以通过不断迭代,找到接近最好的参数
- 也可以使用更加好的算法和模型拿高分
