摘要:scrapy多页爬取识别机制、请求头局部设置
多页爬取 思路
每一次爬取完当前页的信息时,找到下一页的链接
然后用这个yield不断生成请求,每次调用parse继续往下执行1 yield scrapy.Request(next_link, callback=self.parse)
以爬取某网站名人名言为例
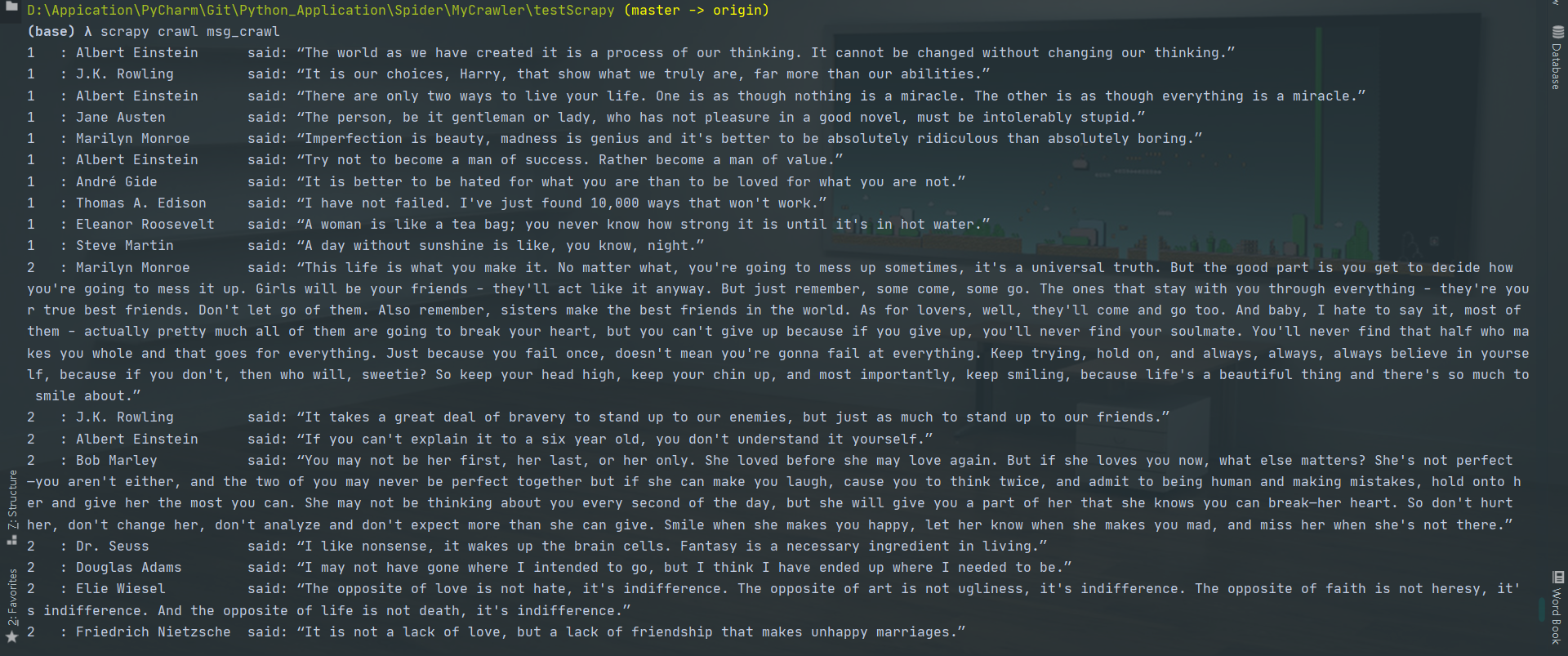
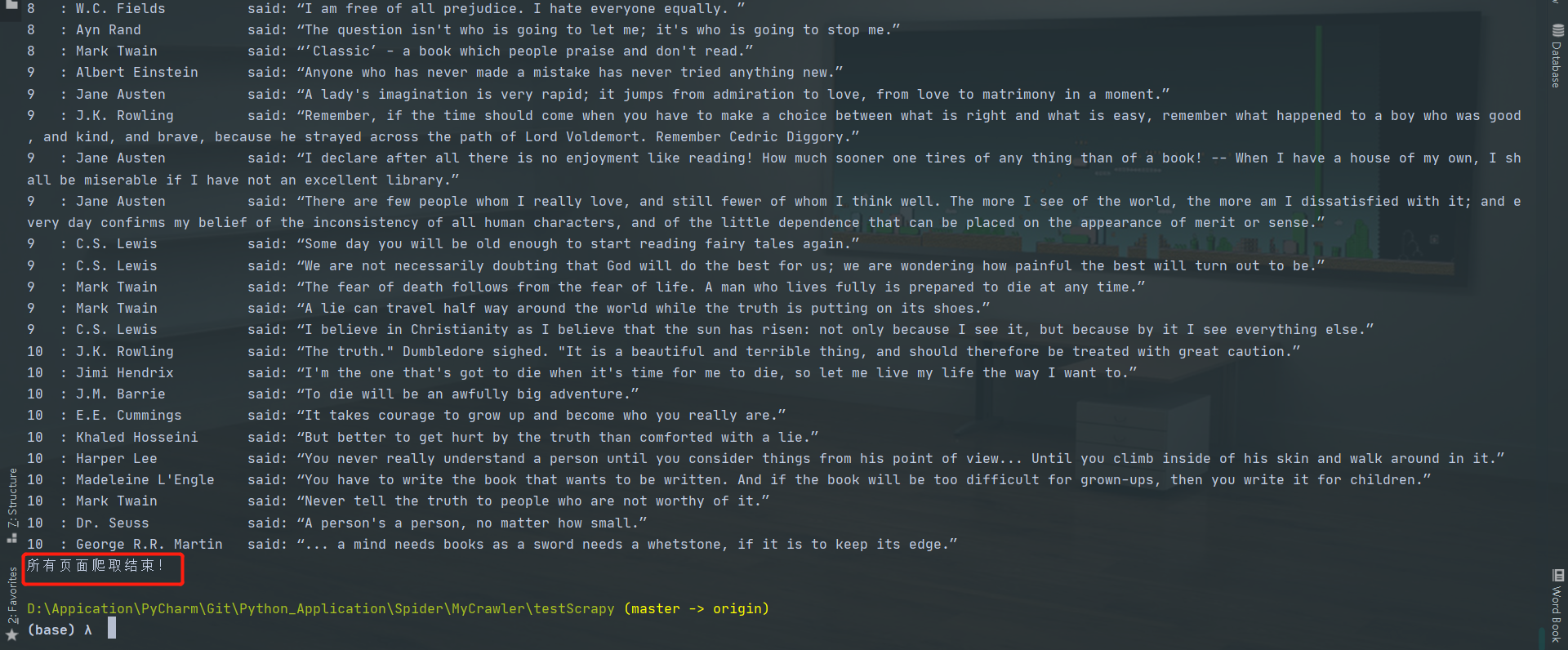
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 """ # @Time : 2020/8/27 # @Author : Jimou Chen """ import scrapyfrom bs4 import BeautifulSoupclass MassageSpider (scrapy.Spider ): name = 'msg_crawl' start_urls = ['http://quotes.toscrape.com/page/1/' ] page_num = 1 def parse (self, response, **kwargs ): soup = BeautifulSoup(response.body, 'html.parser' ) nodes = soup.find_all('div' , {'class' : 'quote' }) for node in nodes: word = node.find('span' , {'class' : 'text' }).text people = node.find('small' , {'class' : 'author' }).text print('{0:<4}: {1:<20} said: {2:<20}' .format (self.page_num, people, word)) self.page_num += 1 try : url = soup.find('li' , {'class' : 'next' }).a['href' ] if url is not None : next_link = 'http://quotes.toscrape.com' + url yield scrapy.Request(next_link, callback=self.parse) except Exception: print('所有页面爬取结束!' )
结果:
注意
scrapy.Request的url参数必须是字符串
最后一页结束时要处理没有下一页链接的情况,可以捕获异常
有些爬不了可能是请求头问题,所以要设置模拟浏览器请求头
爬取豆瓣某书籍评论 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 """ # @Time : 2020/8/28 # @Author : Jimou Chen """ import scrapyfrom bs4 import BeautifulSoupclass CommentSpider (scrapy.Spider ): name = 'comment_spider' start_urls = ['https://book.douban.com/subject/35092383/annotation' ] custom_settings = { "USER_AGENT" : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36' , } page_num = 1 def parse (self, response, **kwargs ): soup = BeautifulSoup(response.body, 'html.parser' ) nodes = soup.find_all('div' , {'class' : 'short' }) print('======================{}======================' .format (self.page_num)) for node in nodes: comment = node.find('span' ).text print(comment, end='\n\n' ) self.page_num += 1 num = 10 * self.page_num if self.page_num <= 28 : url = 'https://book.douban.com/subject/35092383/annotation?sort=rank&start=' + str (num) yield scrapy.Request(url, callback=self.parse)