1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
| """
# @Time : 2020/8/12
# @Author : Jimou Chen
"""
from sklearn.neighbors import KNeighborsClassifier
from sklearn import datasets
from sklearn import tree
from sklearn.ensemble import BaggingClassifier
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
'''一般来说集成学习用于复杂的较好,下面是简单例子'''
def draw(model):
x_min, x_max = x_data[:, 0].min() - 1, x_data[:, 0].max() + 1
y_min, y_max = x_data[:, 1].min() - 1, x_data[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
z = model.predict(np.c_[xx.ravel(), yy.ravel()])
z = z.reshape(xx.shape)
cs = plt.contourf(xx, yy, z)
iris = datasets.load_iris()
x_data = iris.data[:, :2]
y_data = iris.target
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data)
'''建kNN模型'''
kNN = KNeighborsClassifier()
kNN.fit(x_train, y_train)
draw(kNN)
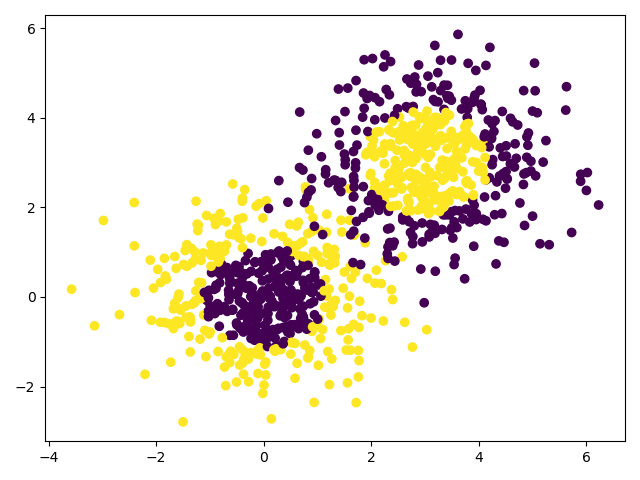
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)
plt.show()
print(kNN.score(x_test, y_test))
'''建决策树模型'''
tree = tree.DecisionTreeClassifier()
tree.fit(x_train, y_train)
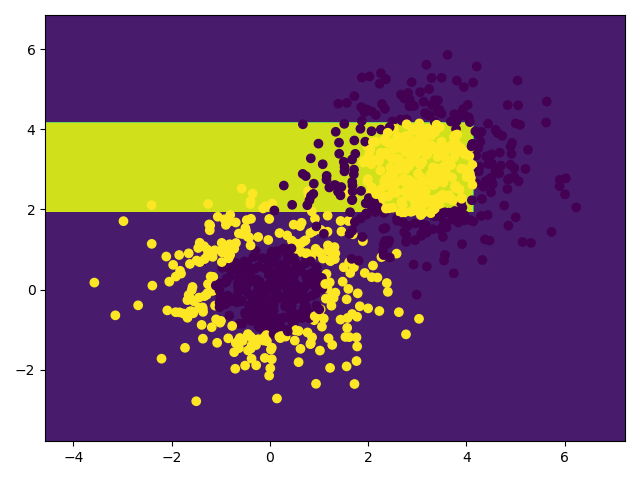
draw(tree)
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)
plt.show()
print(tree.score(x_test, y_test))
'''接下来使用bagging集成学习,加入kNN'''
bagging_kNN = BaggingClassifier(kNN, n_estimators=100)
bagging_kNN.fit(x_train, y_train)
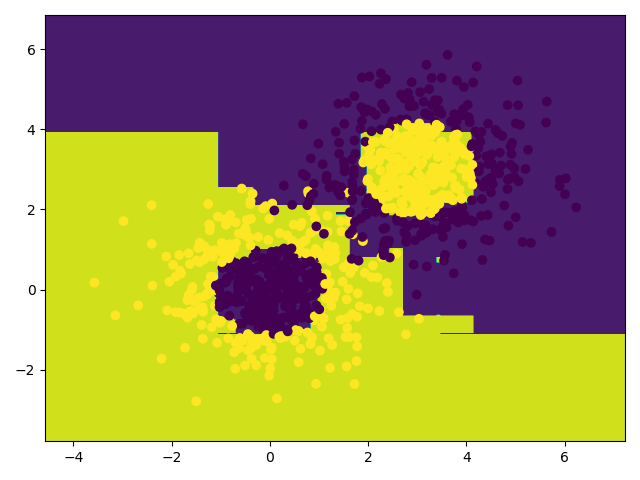
draw(bagging_kNN)
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)
plt.show()
print(bagging_kNN.score(x_test, y_test))
'''加入决策树的集成学习'''
bagging_tree = BaggingClassifier(tree, n_estimators=100)
bagging_tree.fit(x_train, y_train)
draw(bagging_tree)
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)
plt.show()
print(bagging_tree.score(x_test, y_test))
|