摘要:机器学习聚类算法:K-Means、MiniBatchKMeans、DBSCAN算法
聚类算法
K-Means
算法思想:以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果
跟分类相比,没有给定已知标签
用python代码自己实现的Kmeans: https://www.bilibili.com/video/BV1Rt411q7WJ?p=62
- 注意:sklearn自带的KMeans效果要比自己实现的Kmeans效果好
用sklearn实现
1 | """ |
1 | [[ 2.6265299 3.10868015] |
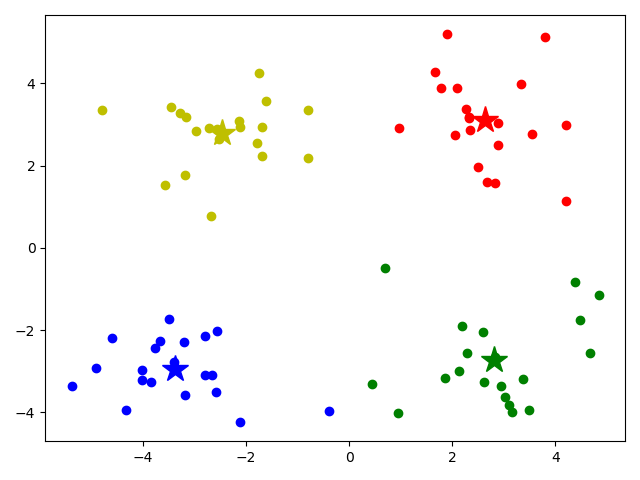
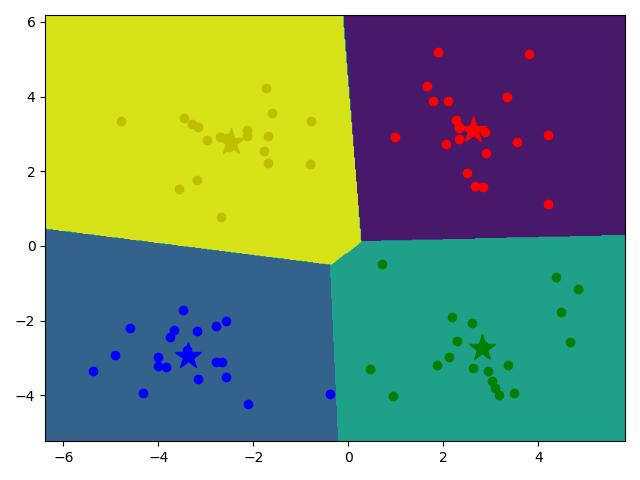
model.fit(data) 只传一个
MiniBatchKMeans模型
- Mini Batch K-Means算法是K-Means算法的变种
- 与K均值算法相比,数据的更新是在每一个小的样本集上。Mini Batch K-Means比K-Means有更快的 收敛速度,但同时也降低了聚类的效果,但是在实际项目中却表现得不明显
1 | """ |
KMeans的4个问题: https://www.bilibili.com/video/BV1Rt411q7WJ?p=65
对k个初始质心的选择比较敏感,容易陷入局部最小值
k值的选择是用户指定的,不同的k得到的结果会有挺大的不同
存在局限性,如下面这种非球状的数据分布就搞不定了
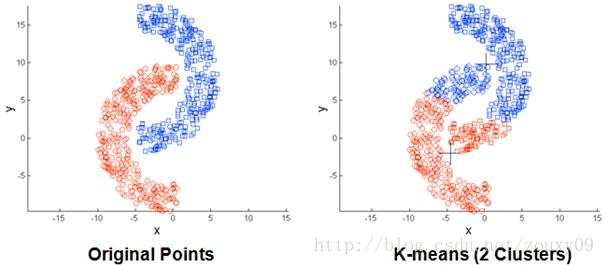
- 数据比较大的时候,收敛会比较慢
DBSCAN
- 本算法将具有足够高密度的区域划分为簇,并可以发现任何形状的聚类
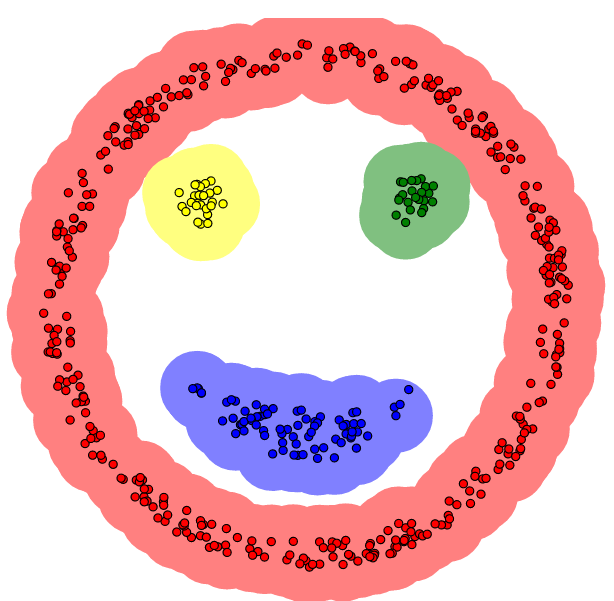
缺点:
- • 当数据量增大时,要求较大的内存支持I/O消耗也很大。
- • 当空间聚类的密度不均匀、聚类间距差相差很大时,聚类质量较差。
DBSCAN和K-MEANS比较:
- • DBSCAN不需要输入聚类个数。
- • 聚类簇的形状没有要求。
- • 可以在需要时输入过滤噪声的参数。
关键参数
esp
min_point
即通过调整eps=, min_samples=来找到一个最好的效果
1 | """ |
1 | [ 0 1 2 3 0 1 2 3 0 1 2 3 0 1 -1 2 0 1 2 3 0 1 2 3 |
- 预测值是-1 的代表噪点
