分类算法
逻辑回归
垃圾邮件分类
预测肿瘤是良性还是恶性
预测某人的信用是否良好
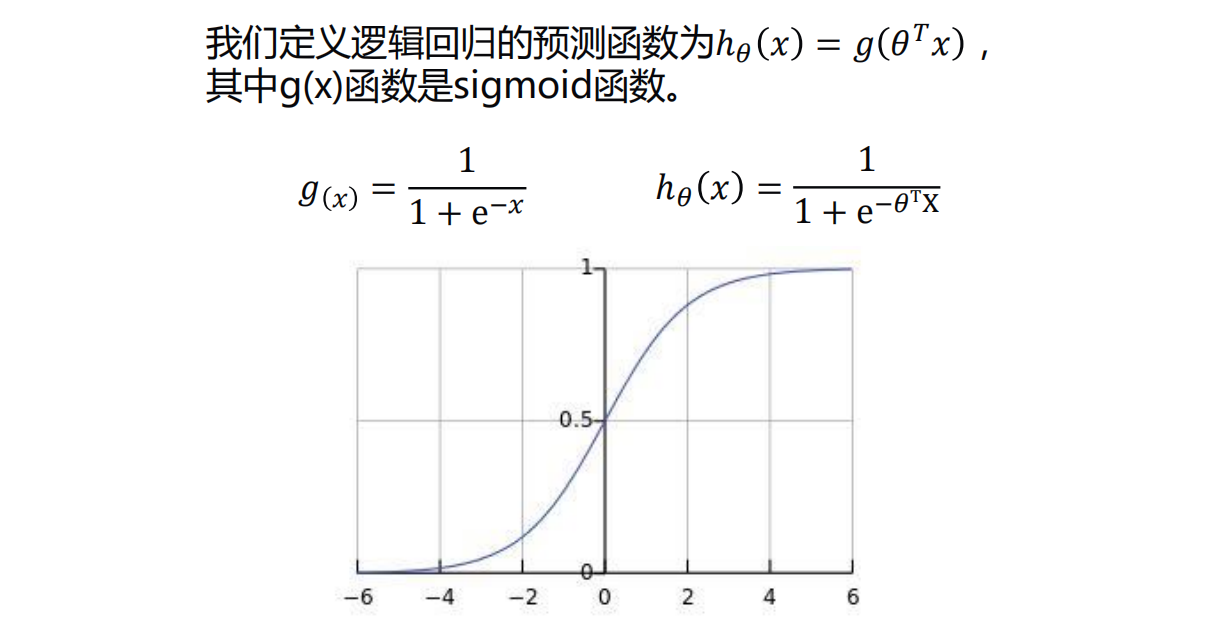
0.5是个分界,上面是g(x)图像
逻辑回归的代价函数
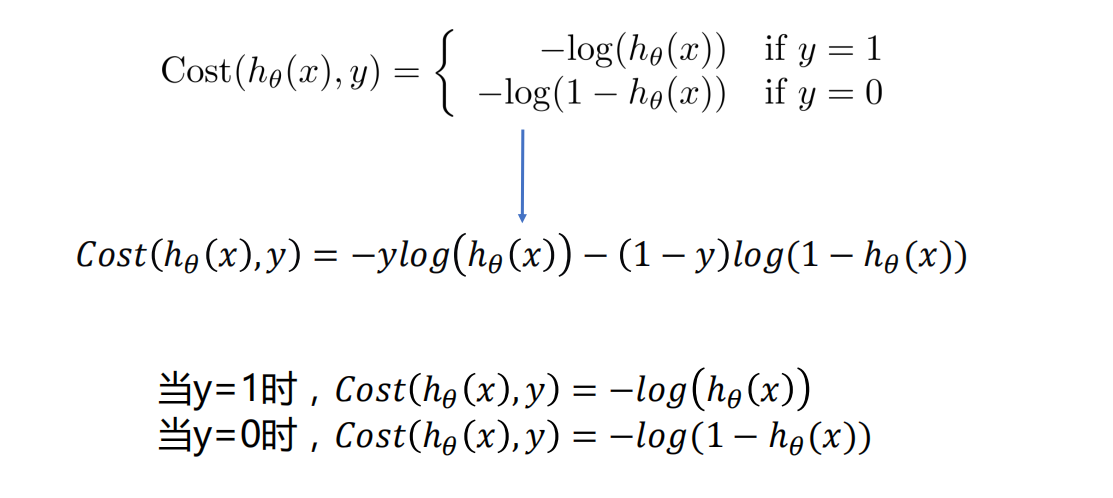
- 一般使用梯度下降法求解
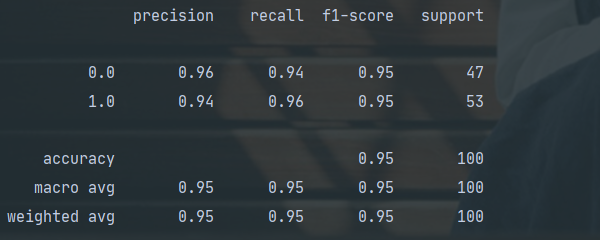
评估分类的结果
- 正确率/召回率/F1指标
正确率就是检索出来的条目有多少是正确的
召回率就是 所有正确的条目有多少被检索出来了

这几个指标的取值都在0-1之间,数值越接近于1,效果越好
某池塘有1400条鲤鱼,300只虾,300只鳖。现在以捕鲤鱼为目的。
撒一大网,逮着了700条鲤鱼,200只虾,100只鳖。那么,这些指标
分别如下:
正确率 = 700 / (700 + 200 + 100) = 70%
召回率 = 700 / 1400 = 50%
F值 = 70% * 50% * 2 / (70% + 50%) = 58.3%
使用classification_report得到正确率/召回率/F1指标
eg
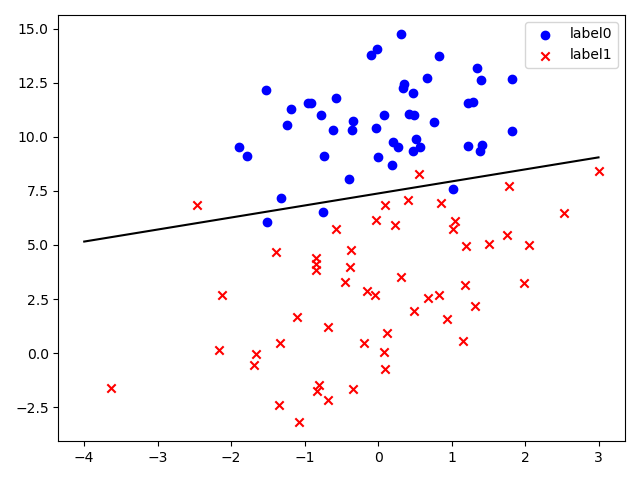
使用梯度下降法解决逻辑回归
1 | """ |
sklearn解决逻辑回归
- 比较方便
1 | """ |

1 | [0. 1. 1. 0. 0. 1. 0. 0. 0. 0. 1. 0. 1. 0. 1. 1. 1. 1. 1. 1. 1. 1. 0. 1. |
由于上面的show_scatter是针对于只有两列特征的,如果是多列特征的话,还要继续切分,道理一样的
model.coef_里面包含了所有带x和y项的系数
model.intercept_是个常数
非线性逻辑回归
数据的扁平化:
eg:[[1, 2], [3, 4]]————>扁平化得到:[1, 2, 3, 4]
非线性逻辑回归可以用梯度下降法或者sklearn实现
sklearn:会更加方便些
sklearn非线性逻辑回归分类
有个更加方便的产生数据的方法:
样本的n_samples,n_features,n_classes可以自己设
相应地,画图时,x_data[:, 0], x_data[0:, 1]也相应的修改
1
2
3
4
5
6
7
8from sklearn.datasets import make_gaussian_quantiles # 用于产生数据集
# 生成数据集,生成的是2维正态分布,可以自己设置类别
# 这里设为500个样本,2个样本特征,类别是2类,也可以设为多类
x_data, y_data = make_gaussian_quantiles(n_samples=500, n_features=2, n_classes=2)
# 可以画出来看看,分类传到颜色c
plt.scatter(x_data[:, 0], x_data[0:, 1], c=y_data)
plt.show()
在使用model = LogisticRegression()和model.fit(x_poly, y_data)建模之前,要产生非线性特征:
1
2
3
4# 定义多项式回归,用degree来调节多项式特征
poly_reg = PolynomialFeatures(degree=5)
# 特征处理
x_poly = poly_reg.fit_transform(x_data)模型评估可以使用model.score(x_poly, y_data),记住是传x_poly
1 | """ |
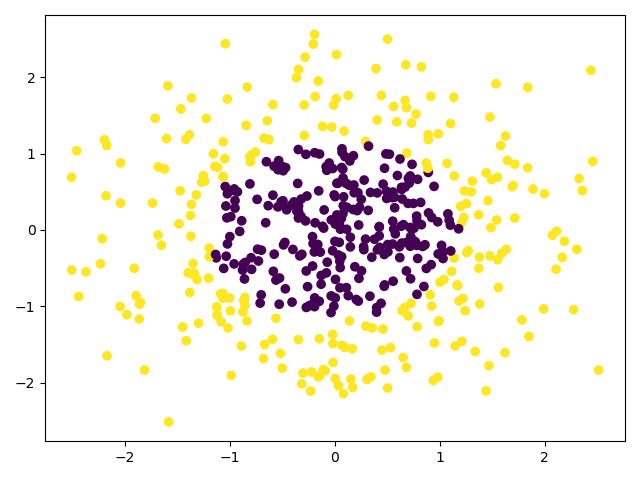
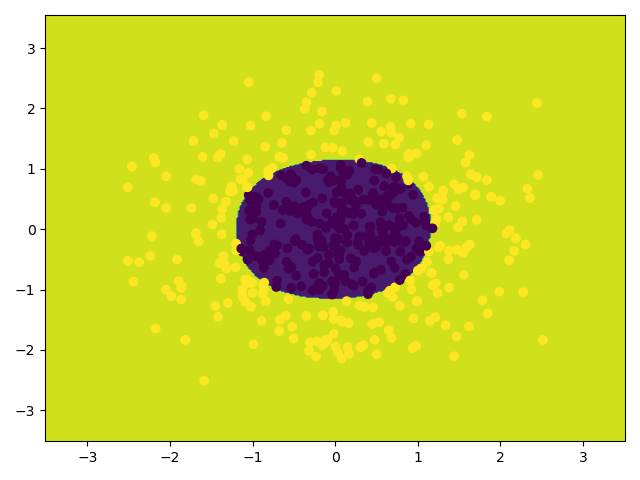
1 | score: 0.988 |
