NN
神经网络
是深度学习的基础
深度学习计算是用GPU算的,比如英伟达

模型收敛条件,即模型训练结束条件
误差 (如代价函数值loss)小于某个预先设定的较小的值
两次迭代之间的权值变化已经很小
设定最大迭代次数,当迭代超过最大次数就停止(用的最多的)
单层感知器
最基础的
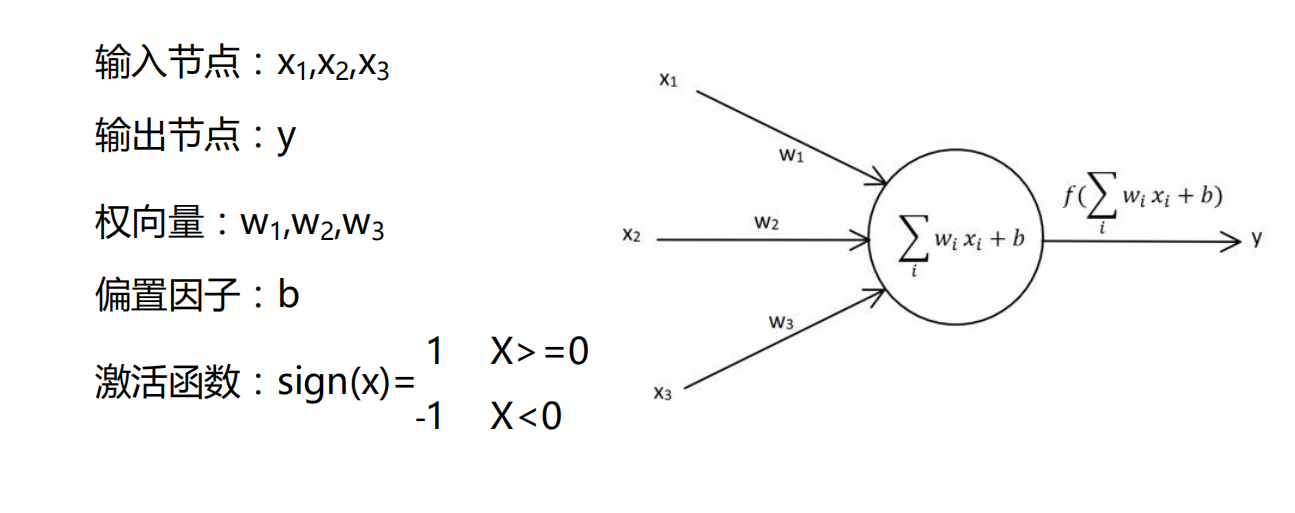
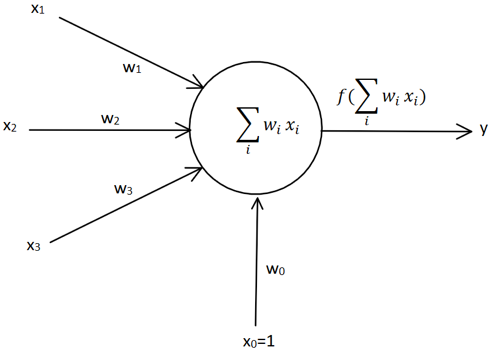
为了矩阵计算时方便一些,将偏置因子b看成是x0*w0
感知器学习规则

eg:
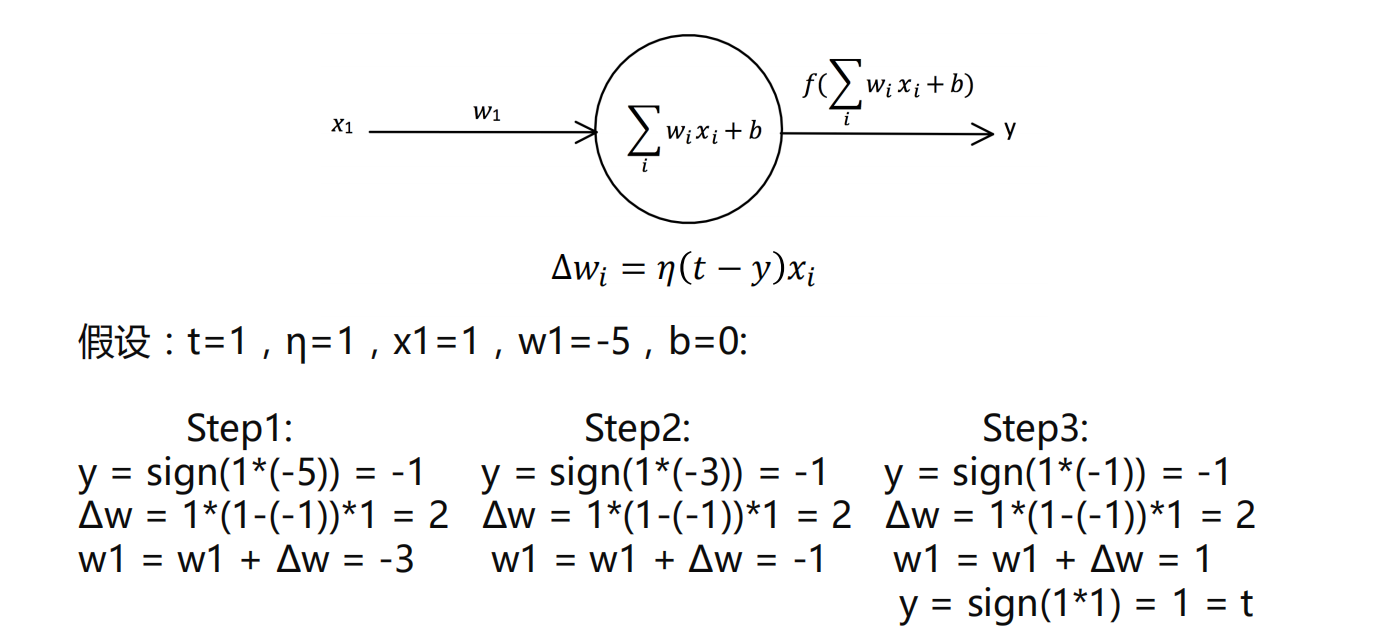
- 步骤就是不断迭代,最后如果y等于正确的标签t,那模型建立就结束
学习率
𝜂取值一般取0-1之间
学习率太大容易造成权值调整不稳定
学习率太小,权值调整太慢,迭代次数太多
代码注意:
一般把输入数据和标签设置成2维的形式
输入m个,输出n个,就把权值设为m行n列(这是随机取权值的情况)
X是个矩阵,X.T则是X的转置矩阵
X,Y是两个矩阵,他们相乘可以写成X.dot(Y),或者numpy.dot(X, Y)
1
np.sign 是自带的激活函数
eg:
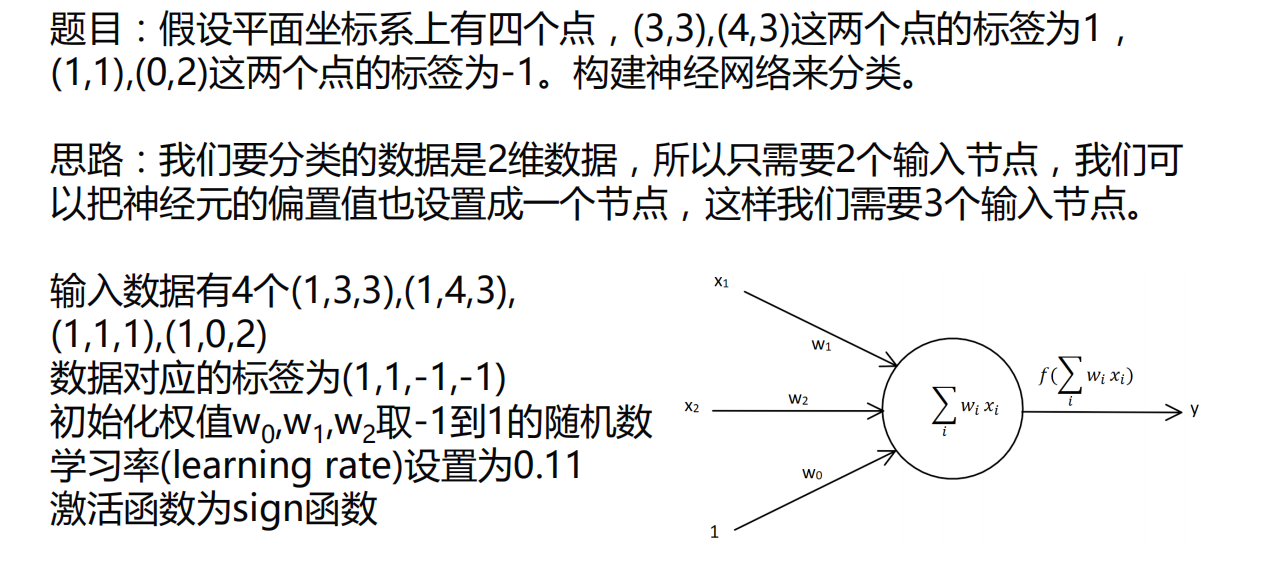
1 | """ |
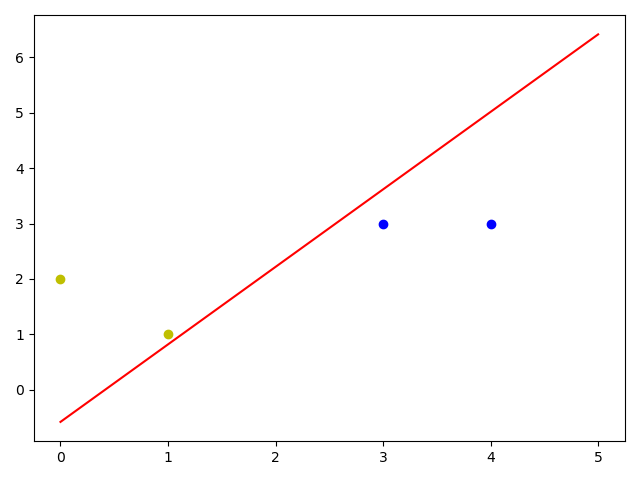
1 | 第0次迭代: |
每次运行结果都不同,因为权值是随机设置的
单层感知器可以帮我们解决一些分类问题
缺点:
- 效果不是很好
- 不能解决非线性的问题,如异或问题
- 因为用的激活函数是sign,所以实际标签只能设1和-1
线性神经网络
线性神经网络在结构上与感知器非常相似,只是激活函数不同。
在模型训练时把原来的sign函数改成了purelin函数:y = x
也就是,把单层感知器的 out = np.sign(np.dot(X, W)) 改成 out = np.dot(X, W)即可
Delta学习规则,比单层感知器复杂
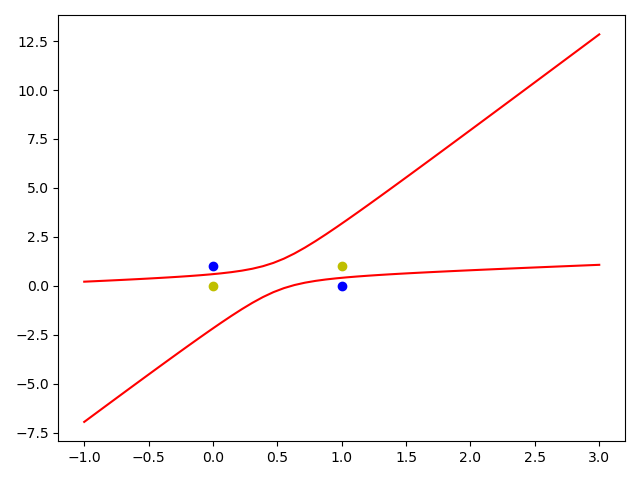
解决异或问题(分类)
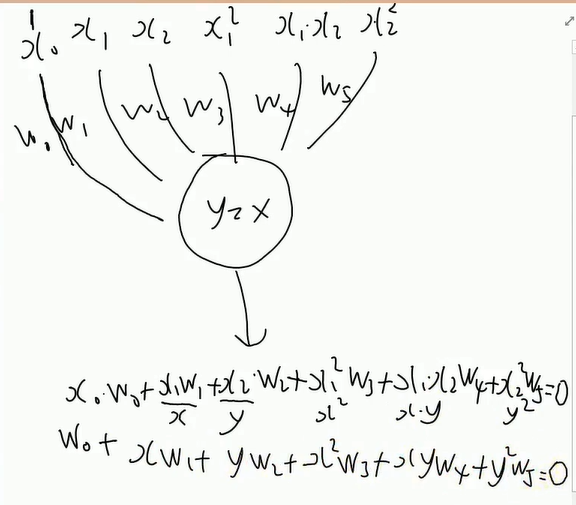
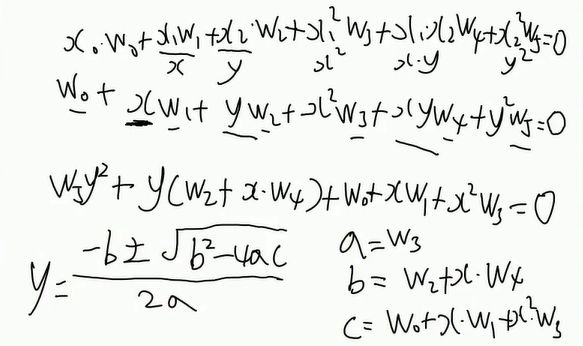
上面a算出来是 w5
1 | """ |
1 | [-1. 1. 1. -1.] #迭代10000次 |
BP神经网络
- 公式推导部分参考教程
